Habana Labs憑什么“叫板”英偉達?
計算力的突破是引燃如今這一輪人工智能發展熱潮的最關鍵因素。而這,也使得人工智能芯片領域近幾年來逐漸成了群雄逐鹿的重要“戰場”。雖然包括英特爾、谷歌、蘋果、華為、百度等在內的國內外各大科技巨頭不斷涌入,但從AI推理預測到AI訓練,截至目前,英偉達的地位似乎仍然難以被撼動。
即便如此,面對這樣一個百億級規模的市場,充滿“野心”的企業還是不在少數,甚至有不少初后起之秀直接“叫板”英偉達。Habana Labs正是其中之一。
成立于2016年,Habana Labs最初的業務是開發專為深度神經網絡訓練和生產環境中的推理部署而優化的處理器平臺。2018年,Habana Labs發布了第一款產品,即AI推理處理器「Goya」;9個月后,Habana Labs又宣布推出AI訓練處理器「Gaudi」,不斷完善自己的產品版圖。
在本周的媒體溝通會上,Habana Labs首席商務官Eitan Medina介紹,其團隊成員主要是來自處理器、DSP、系統設計以及網絡設計等領域全球知名企業的精英,能夠支持Habana Labs從軟件到硬件的研發需求。同時,他還直接“放話”—— 要做人工智能芯片產業的領導者。而其底氣,就是Goya和Gaudi兩款產品。

Habana Labs首席商務官Eitan Medina
AI推理處理器「Goya」:強大性能與高性價比并存
據了解,Goya是一款基于PCle的雙槽位處理器,可基于ResNet-50推理基準實現每秒15,000張圖片的吞吐量,延遲時間僅為1.3毫秒, 功耗僅為100瓦。它主要用于傳統服務器環境,提供推理和預測支持。
“這些數字與英偉達最新的GPU產品T4相比,性能上是其3倍,能耗上是其1/2,而延時也更低。可以說,我們幾乎可以做到實時的圖片處理。”Eitan Medina表示。
 Goya與CPU、GPU在性能方面的對比
Goya與CPU、GPU在性能方面的對比
如何做到?Eitan Medina向記者解釋,無論是GPU還是CPU,其架構都是面向通用計算或常用圖形處理而設計的,因此在人工智能的計算工作中并不具備優勢。而Goya則是完全針對人工智能需求進行的架構設計,這一獨特架構稱為“Tensor processor core”,能夠讓Goya支持不通的神經網絡結構,進而處理不同的數據類型。這就是Goya能夠提供如此高性價比的原因之一。
深度學習中Batch Size(批尺寸,即一次訓練所選取的樣本數)的大小直接會影響到處理器的性能。在GPU中,為了實現其最高性能,需要將這一數值設置得很大,大量數據在同一時間并行處理,這將無形造成計算的延遲。而Goya則可以將Batch Size設置為1,這意味著它可以一次處理1張圖片,并且每秒鐘處理超過7000張圖片。這樣的性能優勢,使得它可以被應用于自動駕駛等對計算延遲要求極高的領域。
除此之外,在云計算場景中,Goya還可以做到多個用戶共享單卡,從而降低用戶的使用成本,讓用戶以更低價格享受更好的產品體驗。
總的來說,Goya優勢有三:一是強大的計算能力,二是高性價比,三是可以實現多用戶之間的計算資源共享。“當然,基于ResNet-50的測試只是我們眾多性能測試的其中之一,除此之外我們還做了很多比較通用的模型測試,可以看到,在這些測試中,Goya也表現出了強大的性能優勢。”Eitan Medina 強調說。
據他介紹,Goya還為用戶提供了一套名為Synapse AI的軟件環境。SynapseAI軟件棧包含一個豐富的內核庫和開放工具鏈,以供用戶添加專有內核。借此,用戶不僅可以直接部署模型、進行定制化操作,同時還能幫助使用CPU和GPU的用戶快速、輕松、準確地將之前的工作部署到Goya上。
AI訓練處理器「Gaudi」:實現本地以太網擴展
再來看一下最新發布的人工智能訓練處理器Gaudi。

Gaudi是一款完全可編程且可定制的處理器,搭載基于第二代Tensor處理核 (TPC™) 并集成開發工具、庫和編譯器。基于ResNet-50,Gaudi可以提供每秒1650張的圖片處理能力——這是在業界單一處理器中最高的計算能力。同時,Gaudi的創新架構可以實現訓練系統性能的近線性擴展,即使是在較小Batch Size的情況下,也能保持高計算力。這意味著,基于Gaudi處理器的訓練性能可以實現從單一設備擴展至由數百個處理器搭建的大型系統的線性擴展。
還是和英偉達的V100相比,基于ResNet-50基準測試,Gaudi所表現出來的計算性能、功耗比和延遲時間仍然相當出色,在速度上要比V100快3.8倍。比如,在性能方面,V100單卡大概每秒處理600多張圖片,而Gaudi單卡則可以處理1600多張;在功耗方面,V100處理600多張圖片的功耗達到了300瓦,而Gaudi處理1600多張圖片的功耗只有150瓦左右。在這方面,Gaudi創造了新的性能紀錄。

Gaudi與V100在性能方面的對比
除了性能,Gaudi還創造了人工智能訓練領域的另一項“行業第一”。其處理器片上集成了 RDMA over Converged Ethernet (RoCE v2) 功能,能夠讓人工智能系統使用標準以太網擴展至任何規模。借此,用戶還可以利用標準以太網交換進行人工智能訓練系統的縱向擴展和橫向擴展。同時,以太網交換機已被數據中心應用于計算系統和存儲系統的擴展中,在速度和端口數方面可提供幾乎無限的可擴展性。在這一方面,與Habana的標準設計相比,基于GPU的系統則依賴于專有的系統接口,對系統設計人員來說,這從本質上已經大大限制了其可擴展性和選擇性。
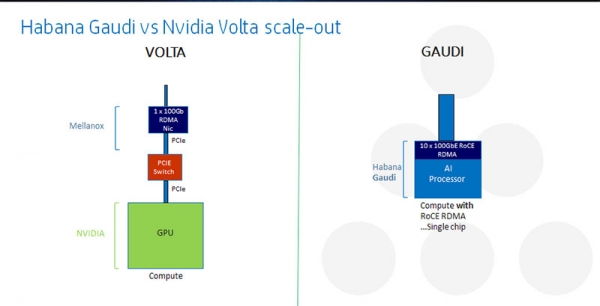
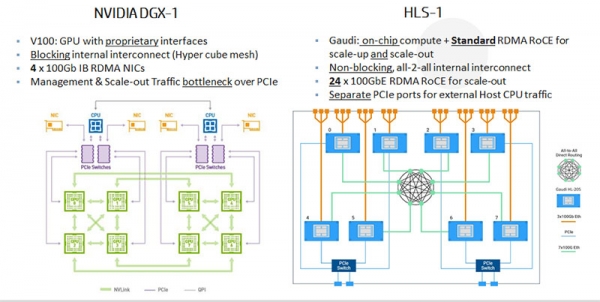
另外,Habana Labs還推出了一款名為HLS-1的8-Gaudi系統,配備了8個HL-205子卡、PCIe外部主機連接器和24個用于連接現有以太網交換機的100Gbps以太網端口,讓用戶能夠通過在19英寸標準機柜中部署多個HLS-1系統實現性能擴展。

HLS-1
Eitan Medina介紹,Gaudi配備的是32GB HBM-2內存,目前提供兩種規格:一種是HL-200 - PCIe卡,設有8個100Gb以太網端口;另一種是HL-205 - 基于OCP-OAM標準的子卡,設有10個100Gb以太網端口或20個50Gb以太網端口。

據悉,Habana Labs將于今年下半年面向特定客戶提供Gaudi的樣品。“通過這幾款產品的推出,我們的第一目的還是推動人工智能芯片領域的進一步發展,幫助這個領域中的用戶解決相關問題,比如計算性能、效率、靈活性等等。”Eitan Medina表示。
本文章選自《AI啟示錄》雜志,閱讀更多雜志內容,請掃描下方二維碼