

第一個開源的具有實時對話能力的多模態模型:Mini-Omni
Mini-Omni是清華大學啟元實驗室開源的多模態模型,具備實時語音到語音的對話能力,無需額外的ASR或TTS模型。它能夠邊思考邊說話,支持流式音頻輸出,并能通過'Any Model Can Talk'方法為其他模型添加語音交互能力。

用 Llama3 70B 打造你的AI投資助手
StockBot是一款AI金融分析機器人它集成了六種@tradingview小部件,包括市場熱圖、財務數據、股票歷史價格、蠟燭圖、熱門新聞和股票篩選器。

英偉達下一款Linux驅動程序開源了,但又沒完全開源
對于英偉達Grace Hopper以及英偉達Blackwell等前沿平臺,您只能使用開源GPU內核模塊。這些平臺不支持專有驅動程序。

META 的全息眼鏡將顛覆數字化互動方式!
當被問及 Meta 最令人興奮的未來產品時,扎克伯格推薦了一款智能眼鏡,該眼鏡配備了攝像頭、麥克風、揚聲器和全視場 (FOV) 全息顯示屏。

AI治理工作中的四大重要經驗
總部于位于得克薩斯州奧斯汀的軟件公司Planview從18個月前起,就開始使用生成式AI提升生產效率。在此期間,他們還嘗試將生成式AI整合進自己的產品當中,構建起可供用戶交互的copilot服務,用于支持戰略投資組合與價值流管理。

一周年 英特爾中國開源技術委員會碩果累累
在2024年這個充滿活力的科技年份,英特爾中國開源技術委員會迎來了它成立一周年的關鍵時刻。這一年里,該委員會不僅加深了與中國開源社區的合作,還通過創新應用和戰略規劃,推動了開源技術在中國乃至全球的快速發展。


CIO指南:采用開源生成式AI需要注意的十件事
企業應該知道該怎么做才能確保他們使用的是經過適當許可的代碼,如何檢查漏洞,如何保持所有內容都已經修補并保持最新狀態。

IBM將量子軟件包Qiskit擴展到全技術棧
IBM今天宣布,將擴展其開源量子軟件工程工具包Qiskit,覆蓋整個軟件開發棧,更好地幫助開發人員為研究和企業應用的量子處理器構建實用的解決方案。

Red Hat闡述和開源社區共同發展AI模型的愿景
Red Hat近日提出了對生成式AI的看法,概述了一種信念:這個正炙手可熱的技術,其未來將取決于開源軟件以及讓用戶社區支持它的能力。

重磅!Llama-3,最強開源大模型正式發布!
Meta發布開源大模型Llama-3,具有80億和700億參數版本,性能在推理、數學、代碼生成等方面有顯著提升。Llama-3采用了分組查詢注意力、掩碼等技術,提高了計算效率。預訓練數據達15T tokens,支持多語言。測試顯示Llama-3性能超過多個知名模型。
實現開源軟件安全,開發人員需要考量的三大關鍵因素
網絡威脅變幻莫測,最近備受矚目的開源軟件安全事件(如 log4Shell、Solar Winds、Colors and Fakers 等)及其對全球數以千計公司造成的災難性影響,凸顯了企業目前在強化數字環境方面所面臨的挑戰。

Cohere發布RAG增強版大模型并開源權重,支持中文、1040億參數
據悉,Command R+有1040億參數,支持英語、中文、法語、德語等10種語言。最大特色之一是,Command R+對內置的RAG(檢索增強生成)進行了全面強化,其性能僅次于GPT-4 tubro,高于市面上多數開源模型。
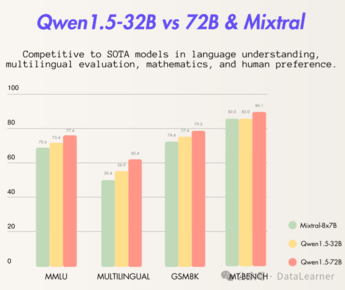
高產的阿里!Qwen1.5系列再次更新:阿里開源320億參數Qwen1.5-32B,評測超Mixtral MoE,性價比更高!
阿里巴巴開源了320億參數的大語言模型Qwen1.5-32B,性能略超Mixtral 8×7B MoE,略低于720億參數的Qwen-1.5-72B。Qwen1.5-32B具有高性價比,顯存需求減半,適合更廣泛使用。模型在多項評測中表現優秀,特別是在推理和數學方面。支持32K上下文長度,以通義千問的開源協議發布,允許商用。

英特爾張開雙臂,欲借開放硬件吸引開發人員
英特爾正努力對外發布尚在開發的硬件,同時輔以對開源的高度重視,希望借此將自身與競爭對手區分開來、吸引更多開發人員使用其云方案。

600GB顯存才能拉起來的Grok-1不太驚艷!馬斯克大模型企業xAI開源Grok-1,截止目前全球參數規模最大的MoE大模型!
馬斯克旗下大模型公司開發的Grok-1大語言模型已開源,采用Apache2.0協議。Grok-1是一個混合專家架構模型,參數總數3140億,每次推理激活860億。雖然在MMLU和GSM8K評測中表現不錯,但與同類模型相比資源消耗大而收益不顯著。開源的僅為推理代碼,訓練基礎設施和tokenizer的特殊token作用未透露。
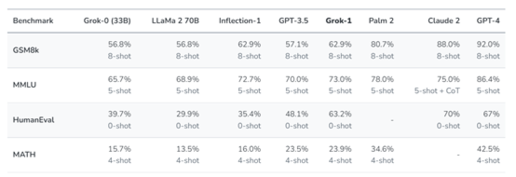
馬斯克將在本周,開源類ChatGPT產品Grok
馬斯克宣布將開源其公司xAI發布的生成式AI產品Grok,一款類ChatGPT產品,提供文本、代碼生成等功能,性能超GPT-3.5但弱于GPT-4。Grok-1在多個測試平臺表現優異,但仍有局限性,如需內容審核,無獨立搜索能力。

DeepSeek-VL:深度求索的多模態大模型
DeepSeekVL是一款開源多模態模型,通過對訓練數據、模型架構和訓練策略的聯合拓展,構建了7B與1.3B規模的強大模型。相關資源可通過論文鏈接、模型下載頁面和GitHub主頁獲取。

