
數據湖 關鍵字列表

數據湖演進之路:架構分裂推動AI分析的新時代
數據湖這個詞在21世紀10年代初出現的時候,有些人認為它是在恰當的時間出現的一種恰當的架構。數據湖是一種非結構化的數據存儲庫,利用了新的低成本云對象存儲格式(如Amazon S3),可以容納來自網絡的大量數據。


AWS與IBM Netezza都已支持Iceberg表格式
云巨頭AWS選擇通過表格式Apache Iceberg將Redshift數據倉庫向數據湖延伸,IBM Netezza也是如此。

探索“智能湖倉”,構建企業發展“內生動力”
作為全球領先的云上數據平臺“智能湖倉”架構的提出者,3月14日,亞馬遜云原生數據湖S3迎來17周歲。Amazon S3將繼續引領云原生技術的革新,推動云計算技術的廣泛應用和發展。
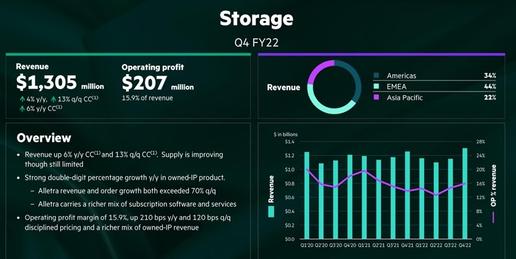
迎合GREENLAKE業務環境需求,HPE出手增強ALLETRA存儲解決方案
本周,在HPE業務中增速可觀的這一Alletra產品家族迎來更新,正式接納“Sapphire Rapids”至強SP處理器。

戴爾科技滕昱:高性能對象數據湖 助力新型工作負載
滕昱受邀接受至頂網的采訪,分享了高性能對象數據湖對于現代化應用的價值以及戴爾科技在高性能對象數據湖領域的創新。

解鎖“暗數據”的隱藏價值
當IT領導者們試圖從企業收集的數據中獲取商業價值的時候,他們面臨著無數挑戰。或許最不為人知的是,沒有很好地利用那些已經生成的、頻繁保存的、但卻被很少使用的數據,正在讓他們錯失各種機會。
Ozone | 數據湖存儲,“統一”和“融合”哪個更好?
技術體系繁雜,存在著很多“平行宇宙”。今天,潭主跟大家分享最近學習的一個數據湖存儲技術,Ozone。
騰訊云展示云原生數據湖全景圖,布局多元化數據分析場景
5月13日,在北京舉辦的“騰訊云原生智能數據湖”發布會上,騰訊云首次對外展示完整云端數據湖產品圖譜,并推出兩款“開箱即用”數據湖產品,數據湖計算服務DLC和數據湖構建DLF。


公共事業CIO:別讓有價值的數據埋沒在數據湖中
隨著全球企業手中數據量的快速增長,高級分析正成為各類業務活動的核心。消化數據、運用數據,企業才能夠做出更明智的業務決策。


白皮書